네이처 게재 초고난도 AI 벤치마크
총 2500문항…국내 연구진도 출제 참여
전 세계 주요 인공지능(AI) 모델들이 인류가 만든 기존 시험을 손쉽게 통과하는 가운데 이들조차 풀지 못한 초고난도 벤치마크 '인류의 마지막 시험(Humanity's Last Exam·HLE)'이 공개됐다.

기사 이해를 돕기 위한 인공지능(AI) 이미지. 픽사베이
29일 국제학술지 네이처에 실린 HLE는 수학·과학·인문학 등 100여개 학문 분야 2500문항으로 구성된 AI 학술 시험으로 한국 연구자들도 문제 출제에 참여했다.
HLE는 미국 비영리단체 AI안전센터(CAIS)와 스타트업 스케일AI가 지난해 1월 처음 공개한 프로젝트로 약 1년간의 검증을 거쳐 공식 논문으로 발표됐다. 최근 AI 성능이 급격히 향상되며 기존 벤치마크들이 사실상 무력화되자 이를 대체할 새로운 기준을 만들기 위해 기획됐다.
100여 개 학문 총망라…AI도 못 푼 문제만 선별
시험 문항은 수학·물리학·화학·생물학·공학·컴퓨터과학·인문학 등 100여 개 세부 분야를 망라한다. 일부 문항은 텍스트와 이미지를 함께 이해해야 하는 멀티모달 문제로 구성됐다. 50개국 500여 개 기관 소속 교수·연구자 약 1000명이 출제에 참여했으며 출제 당시 최고 성능의 AI도 풀지 못한 문제만을 선별해 최종 문항으로 남겼다.
전체 문항 중 수학 비중이 41%로 가장 높다. 묘비에서 발견된 로마 비문 일부를 번역하거나 벌새의 종자골이 지지하는 힘줄의 쌍 수를 묻는 등 분야별 전문 지식을 요구하는 문제가 다수 포함됐다.
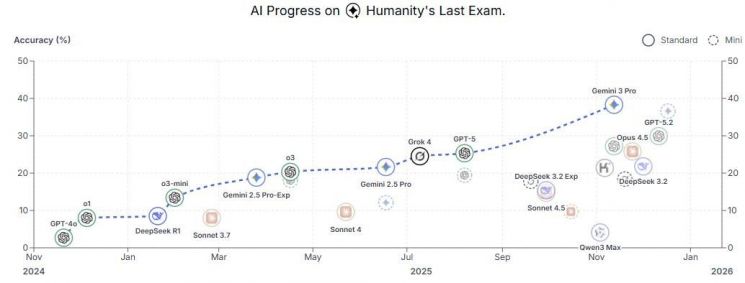
주요 AI의 HLE 벤치마크 점수. CAIS
현재까지 AI들은 HLE에서 낮은 성적에 머물고 있다. CAIS가 공개한 평가 결과에 따르면 구글 '제미나이 3 프로'가 정확도 38.3%로 가장 높은 점수를 기록했으며 오픈AI의 GPT-5.2는 29.9%, 오푸스 4.5는 25.8%, 딥시크 3.2는 21.8%에 그쳤다.
국내 AI 모델의 성적도 아직은 제한적이다. 텍스트 문항만을 대상으로 한 평가에서 LG AI연구원의 '엑사원(EXAONE)'은 13.6%, 업스테이지의 '솔라 오픈'은 10.5%, SK텔레콤의 'A.X K1'은 7.6%를 기록했다.
국내 연구자도 출제 참여…"AGI 판단 기준은 아냐"
논문에는 AI 스타트업 에임인텔리전스의 박하언 최고기술책임자(CTO), 김대현 연세대 교수를 비롯한 국내 기관 소속 연구자 6명도 이름을 올렸다. 박하언 CTO는 "복잡한 계산이 필요한 이산수학 문제를 출제했다"며 "AI가 풀이는 비슷하게 하지만 답에서 숫자 차이가 나게 되는 문제"라고 설명했다.
다만 연구진은 HLE 성적을 범용 인공지능(AGI) 도달의 기준으로 해석하는 데는 선을 그었다. 높은 점수는 전문 지식과 추론 능력의 향상을 의미할 뿐 인간처럼 새로운 연구를 주도하는 단계에 이르렀다는 뜻은 아니라는 설명이다.
박 CTO는 "HLE가 '마지막' 벤치마크가 될 것이라고 보지는 않는다"며 "AI 안전성과 실제 행동을 평가하는 영역 등 아직 비어 있는 벤치마크가 많다"고 말했다.
에임인텔리전스도 한국 인공지능안전연구소(AISI)와 함께 AI의 안전한 의사결정을 평가하는 새 벤치마크 '심판의 날(The Judgement Day)'을 개발하고 있다. 구글 딥마인드, 엔비디아, 옥스퍼드대와 협력하고 있으며 현재 안전 시나리오를 모집하고 있다.
박은서 인턴기자 rloseo8@asiae.co.kr
<ⓒ투자가를 위한 경제콘텐츠 플랫폼, 아시아경제(www.asiae.co.kr) 무단전재 배포금지>